场景是这样的:我传入一个商品参考图,我希望使用nano Banana2输出一个模特+商品图完美融合的图片。
这是我的原参考图:


紧接着我让gpt和gemini帮我调了无数版提示词,但效果不尽人意.
这是我一堆输出的图片:
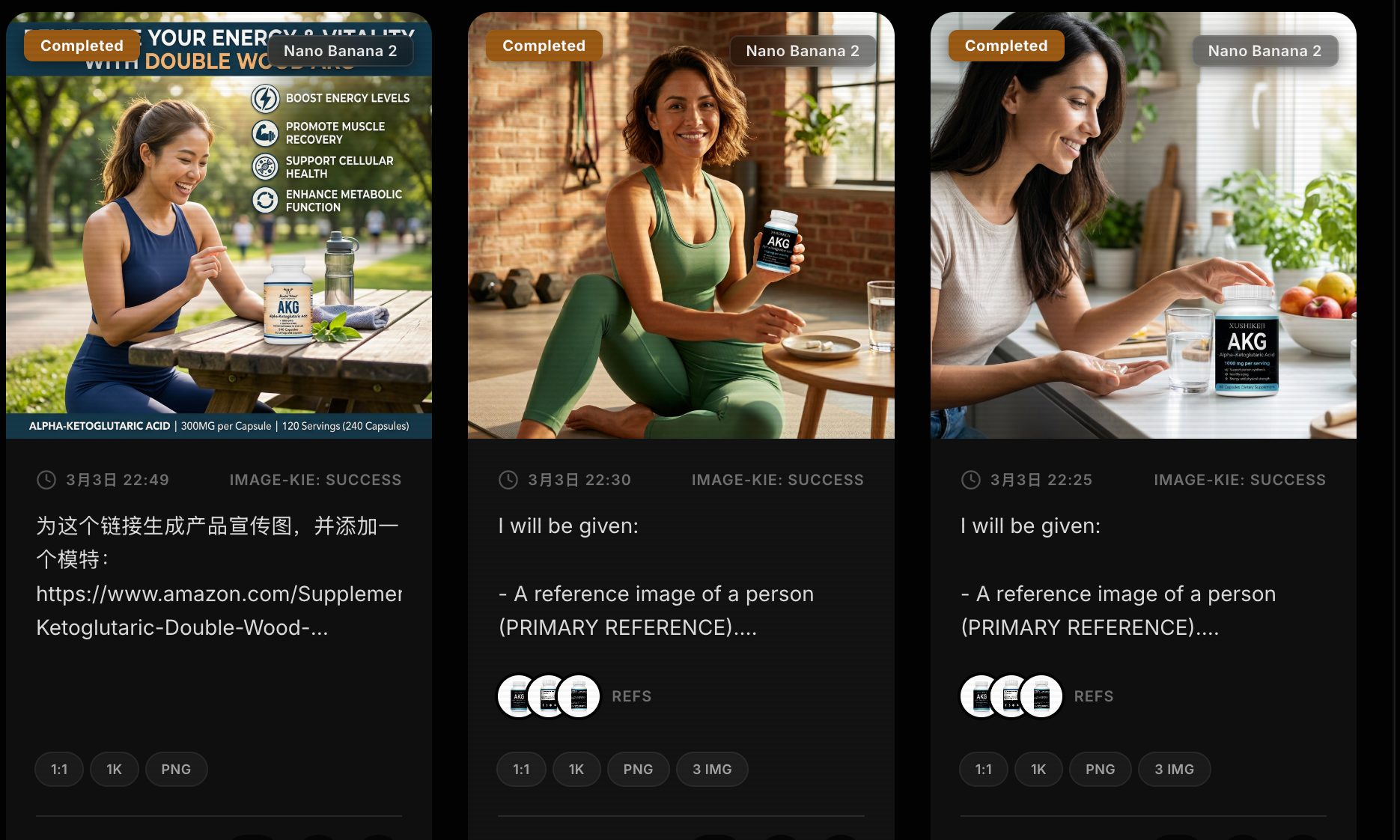
问题总是出现在产品完全就像贴上去一样,融合度很差,很假。紧接着我去reddit、twitter、ytb、各种各样的提示词网站查看大量的例子和提示词模版什么的,但没找到什么好的解法。
当没啥能抄的,且AI的答案也很烂的时候,于是我觉得这可能确实需要我自己发挥一些思考能力了,扩展一下认知了。
回到人上
人为什么会觉得一个东西是真实地存在于画面里,而不是后期硬贴上去的?
我倾向于把它理解成“一致性判断”。人眼很多时候并不会逐项分析“这个东西像不像”,而是会很快扫一遍:它和周围是不是属于同一个物理环境。同一套光线、同一套空间关系、同一套成像特征,只要其中几项对不上,违和感就会马上出来。
而我们继续向下拆解,我让AI把这种判断大致拆成 6 个维度。它们不一定每次都同时起作用,但只要有一两项明显出戏,整张图就会显得假。
1. 光照一致性
这是最容易露馅的一项。人会下意识看这些东西:
-
光从哪来?
-
阴影方向是否统一?
-
高光是否在合理位置?
-
色温是否一致?
如果产品是冷白棚拍光,人物和环境却是偏暖的室内光,或者阴影方向压根对不上,哪怕说不清问题在哪,也会本能地觉得不真。
2. 接触和受力关系
人对“东西有没有真的碰到”特别敏感:
-
手有没有压到物体?
-
皮肤有没有轻微形变?
-
物体有没有重量感?
-
是否有遮挡关系?
比如没有遮挡,就会像悬空;手指没有任何挤压或形变,就像没碰到;没有贴地阴影,也很难让人相信它和场景在同一个空间里。说白了,大脑在看这个物体有没有真的“受力”,有没有真的和别的东西发生关系。
3. 透视、比例和镜头感
这一类问题往往更隐蔽,但也很致命:
-
消失点是否统一
-
焦距是否匹配
-
景深是否一致
-
模糊程度是否合理
如果人物已经有明显的景深虚化,产品却锐得像单独导出的电商图;或者人物是广角感,产品却像长焦压缩出来的,那种“贴纸感”就会非常强。
4. 环境染色
真实世界里的物体,不会是完全独立、绝缘的。它会被周围环境影响:
-
环境光会染色
-
物体会反射周围色彩
-
阴影会有色温变化
所以一个商品如果干净得像刚从白底图里抠出来,边缘和表面完全没有吃到环境色,马上就会像单独一层。
5. 噪声、锐度和纹理
真实照片通常会有统一的成像特征:
-
噪点一致
-
压缩纹理一致
-
清晰度分布一致
如果人像带一点柔焦、压缩痕迹和传感器噪点,产品边缘却干净得像矢量图,观感上就不是“同一张照片”,而像两张东西拼在一起。
6. 场景和动作是否说得通
最后还有一个经常被忽略的维度:语义合理性。也就是这件事本身像不像真的会发生。
-
这个姿势合理吗?
-
这个产品在这个场景合理吗?
-
这个人会这样拿吗?
哪怕光影都做对了,如果动作很别扭、拿法不符合常识、产品出现在一个很奇怪的语境里,人还是会觉得假。
归纳一下
真实感并不只是“细节很多”,而是很多细节之间彼此不打架。
多个物理统计特征同时一致。
回到模型上
那这对于模型来说意味着什么?
我后来想明白的一点是:就算现在很多图像模型底层已经不是传统的 U-Net diffusion,而是 Transformer + MoE 这种架构,但真正决定结果的那套规律其实没有变。
架构会影响容量、表达能力和条件建模方式,但不会改变一件更底层的事:
模型最后还是要生成一张“看起来像训练数据里会出现的图”。
所以前面说的人眼在检查一致性,放到模型这边,其实可以翻译成另一句话:
哪些描述,真的会改变图像里大范围的结构关系?
如果一个描述能稳定地映射到光影、空间、遮挡、边界这些东西,它通常就是高权重变量。反过来,如果只是“自然一点”“真实一点”这种抽象评价,模型大概率只会把它当成很弱的风格偏好,因为收缩的范围是不够的。
结构约束
不管底层具体叫什么名字,图像生成本质上都离不开几件事:
-
建立全局一致的亮度和空间关系
-
维持物体之间的前后顺序
-
让局部细节不要破坏整体结构
这也是为什么,像光照、遮挡、投影、透视这种东西,一直都比“高清”“自然”“高质量”更有用。
比如“左上方单主光”在训练数据里通常就意味着:某一侧更亮,另一侧更暗,阴影方向相对统一,高光落点也更可预测。模型一旦读到这种描述,能落下去的东西是很具体的。
但“真实”“自然融合”不是这样。它们的解释空间太大了,可以是棚拍,可以是街拍,可以是电影感,也可以是手机随手拍。模型很难从这种词里推导出明确的结构改动。
哪些元素对模型来说权重更高
如果只看“哪个变量最容易真正把图改掉”,我现在会把顺序排成这样:
1. 光源和光照方向
这是最强的单一控制杆。
因为它影响的不是局部细节,而是整张图的大面积明暗分布。阴影往哪边走、体积感怎么出来、亮面和暗面怎么分,都跟它有关。它一旦定下来,很多区域都会被一起约束。
2. 遮挡关系
遮挡会直接改变空间拓扑。
比如“产品被手指部分遮住”这种描述,不是在加一个细节,而是在强行规定谁在前、谁在后、边界在哪里断开。模型只要真的执行了这句话,画面的空间关系就会立刻更像同一个场景里的东西。
3. 投影
投影很重要,因为它会把两个原本独立的对象绑在一起。
一旦你写“产品在手上投下阴影”,模型就不能只把产品画对,它还得处理产品和手之间的光学关系。这个约束比“看起来自然”强得多,因为它要求跨区域一致。
4. 透视、焦距和景深
这一类变量决定的是“是不是像同一台相机拍出来的”。
如果人物是浅景深、偏写真的镜头感,产品也必须跟着进入同样的透视和模糊分布;否则就很容易保留那种标准商品图的锐利边缘,最后看起来像贴图。
5. 接触和受力
这一项未必像光照那样影响全局,但对真实感帮助很大。
手指轻微压到瓶身、皮肤边缘有一点挤压、握持姿势符合常识,这些都在告诉模型:这不是两个摆在一起的元素,而是真的发生了接触。
为什么抽象词通常权重低
像这些词:
-
realistic
-
natural
-
seamless
-
high quality
-
perfect integration
不能说完全没用,但它们更像一个模糊的方向修正,而不是可执行约束。
原因很简单:它们不会明确指定画面应该怎么变。模型可以轻微调整风格,也可以几乎无视,因为这类词没有强迫它去重建边界、改写阴影、重排前后关系。
换句话说,抽象词的问题不在于“抽象”,而在于它不收缩解空间。
“自然”可以对应很多种图。
“左上方柔光,产品被手指部分遮挡,并在手背投下阴影”对应的图,就少得多。
后者更难被模型敷衍过去。
这件事对写提示词的实际启发
如果目标是让产品不再像贴上去的,那提示词最好少写评价,多写关系。
比起说:
make it natural
不如明确描述这些东西:
-
光从哪来
-
影子往哪落
-
产品被哪里遮住
-
手是怎么拿住它的
-
有没有轻微受力和接触
-
透视和景深要不要匹配场景
因为这些描述一旦成立,模型就不只是“知道你想要自然”,而是被迫去补齐自然背后的那套物理关系。
然后我们同事给我了一个 Tips,是描述产品的具体尺寸会有很好的效果。
我后来觉得,这个建议本质上也是在补结构约束。
乍看之下,“12cm 高”“直径 3cm”这种描述像是在补商品信息,但模型真正利用的,通常不是“它记住了一个精确数字”,而是这个数字背后隐含的一整组空间关系:
-
这东西相对手来说到底算大还是算小
-
手指应该包住多少面积
-
遮挡比例应该落在哪个范围
-
握持姿势是否合理
-
它在镜头里看起来应该离人多近
所以尺寸之所以有用,不是因为它让模型更懂参数,而是因为它在收缩“相对尺度”这件事的解空间。
比如手看起来像是在捏一个很小的东西,产品却被画得偏大;或者产品视觉上应该更厚、更重,但手的张开幅度和受力方式完全不像在拿这个尺寸的物体。只要这种尺度关系错了,画面就很容易露馅。
如果把它放回前面那几个高权重变量里看,我会觉得尺寸不是第六种独立约束,它更像一个更上游的尺度先验,会同时影响:
-
遮挡关系
-
透视、焦距和景深
-
接触和受力
-
投影范围和形状
但它对光源方向本身的控制是比较弱的。也就是说,它更像是在帮前面那些约束落地,而不是替代它们。
所以更准确的说法是:
尺寸本身不是重点,重点是它能把比例、遮挡、握持和受力一起钉住。
也正因为如此,很多时候写一个明确的尺寸,确实会比写一堆 realisticseamless 这类抽象词更有效。
通用解
这篇文章真正有价值的地方,不在“商品图融合”这个具体案例,而在它给了一个更通用的看模型问题的方法:
当模型输出不对时,人应该从哪一层介入?
显然不是继续堆形容词,也不是反复抽卡“更真实一点”“更自然一点”。
真正通用的解法是:先把失败拆成结构问题,再把结构问题翻译成模型能执行的约束。
不止是说“这次这个场景该怎么写”,以后不管你碰到的是:
-
图像里东西像贴上去的
-
文本里逻辑像拼出来的
-
视频里动作衔接不成立
-
agent 会做表面动作,但任务闭环不完整
都可以先问同一个问题:
它到底是哪个结构关系没立住?
是边界错了,顺序错了,因果错了,尺度错了,还是上下文约束根本没给?
一旦问题被定位到这一层,后面的处理方式通常就会清楚很多。因为你不再是在和一个模糊结果较劲,而是在补它缺失的约束。
所以所谓的人治,真正重要的也不是“人来微操模型”,而是人来做两件模型不擅长的事:
-
定义什么叫错
-
指定哪些关系不能错
模型擅长的是在分布里补全,人擅长的是在更上游定边界、定规则、定判据。
边界给对了,模型才更容易落到对的解;边界不给,模型就会持续产出那种“局部像对了、整体其实不成立”的东西。