我发现现在整个市场对于 OpenClaw 有一种很盲目的迷信和过度的预估。
很难有开源项目像OpenClaw符合这么多方的利益:模型厂商,平台方,课程方, 开发者,硬件厂商,KOL 等。
东西确实是好东西,它也一定是进步的,但因为利益催化,导致大家直接跳过技术成熟开始竞赛了,就导致非常急、非常野蛮。而这个早期恶果是由大批不明所以和想尝鲜的用户来承担的(不管是天量的Token消耗、还是浪费大量的调试时间等等等)。
因此我分享一些专门针对OpenClaw进行调优的方案,不管是对于开发者、还是普通用户来说,都能花费更少的Token去获得更好的结果。
很多人会认为:
Agent = 会自动变聪明
但实际上更接近:
Agent = 一堆机制 + Prompt + Tools
如果没有设计约束,它最终会变成一个混乱的自动化系统,而不是一个可靠的助手。
当我们来到 OpenClaw 的 Workspace,会看到各种凌乱的 Skills、几百个 Markdown 的 Memory、各种奇怪的配置。
举个例子:我有 8 个工作流,其中 4 个是从 ClawHub 下载的,另外 4 个是我自己写的,我自己写的 4 个打开的是 Profile-xxx 的浏览器,另外 4 个打开的是调试浏览器。这时候就会很头疼,因为我希望浏览器制定Profile是一致的,也希望各种 Skills 能复用同一浏览器实例。
另外,因为很多 Skill 都有独立的 node_modules 或 _cache,整个 OpenClaw 会莫名其妙地吃掉大量运行时内存。再加上太多 Memory(长记忆那个文件夹,里面全放原始MD文档) 没有 Embedding,还会耗费巨量上下文。
这其实和我期望的那个像贾维斯一样的Assistant差得很远。我的 Claw 叫 Echo (这是个 Go 框架的名字,其实我是希望它帮我做社媒啥的,因为我不是很擅长),它应该像一个聪明的小伙伴,能在消耗少量上下文的同时,不打扰我,精准完成任务,然后再通知我;而不是我需要一直修正它、教它。
那怎么让 Echo 变聪明?我觉得要先从 OpenClaw 的关键机制和架构讲起,加强对事情本身的认知,自然能够让AI更好的输出东西来帮助我们、也自然能开发更好的 Plugin 和 Skills。
OpenClaw 的整体架构
这是一张整体的OpenClaw架构图,可以帮大家建立一个大体的概念。

但实际上我们可以简化,OpenClaw 本质上是一个 Agent Runtime + Gateway 平台。
User
↓
Gateway
↓
Agent Runtime (Pi)
↓
LLM
↓
Tools / Skills
↓
External Systems
如果把它拆开来看,里面最关键的几层其实就是 Gateway、Agents、Sessions、Memory、Tools 和 Workspace。它们共同组成了一个能持续运行、能调用工具、也能保存状态的 Agent 系统。
上下文、记忆与检索
先看最核心的一组东西:Session、Memory 和 Embedding。它们分别处理短期上下文、长期记忆,以及长期记忆的语义检索。
Session 可以理解成 OpenClaw 的短期上下文系统。本质上,它就是一份 append only transcript,也就是只追加、不回写的对话记录。通常会放在下面这样的路径里(单 Agent 的情况下):
agents/main/sessions/*.jsonl
一条 session 记录里,一般会包含 user message、assistant reply、tool call 和 tool result。这些内容堆起来之后,就构成了下一次 LLM 调用时所依赖的上下文。
但问题也很明显:如果只是一味追加,session 会越来越长,最终把上下文窗口拖垮。所以 OpenClaw 会在这里做三层处理。
第一层是 Pruning。它主要用来删除旧的 tool output,通常发生在每次 LLM 调用之前。这个动作是临时的,目的是控制上下文体积,并不会真的改写历史。
第二层是 Compaction。就是很常见的把旧对话压缩成摘要,再用摘要替换掉原本那部分历史,所以它是永久性的,会直接修改 session transcript。流程大致是:
old messages
↓
summary
↓
replace history
第三层是 Memory Flush。它通常发生在 compaction 之前,Agent 会先把重要信息写进 memory,再去压缩上下文。这样做的目的很直接,就是避免那些长期有用的信息随着摘要化过程一起丢掉。
如果说 Session 负责眼前这一轮对话,那么 Memory 负责的就是长期记忆。它不是某种复杂数据库,而是非常朴素的文件系统记忆,典型结构一般长这样:
[MEMORY.md](http://MEMORY.md)
memory/[YYYY-MM-DD.md](http://YYYY-MM-DD.md)
它的特点其实很符合 OpenClaw 的整体哲学:human readable、appendable、versionable。也就是说,人能直接读,系统能持续追加,版本管理工具也能很好地追踪变化。
Files are the source of truth
这句话几乎就是 OpenClaw 对 Memory 的基本态度。文件本身才是真正的事实来源,其他机制只是围绕文件做索引、检索和组织。
在使用方式上,Memory 大致有两条路。第一条是 Semantic Search,也就是 Embedding 检索。如果配置了 memorySearch,它的流程通常会是:
memory files
↓
embedding
↓
vector index
↓
semantic retrieval
第二条是 Direct Prompt Injection。如果没有配置 embedding provider,系统就更接近下面这种做法:
memory files
↓
direct prompt injection
这时候 Memory 依然存在,也依然能起作用,只不过它没有语义检索能力,更多还是靠直接注入 prompt 来参与上下文构建。
Embedding
Embedding 属于 memorySearch 这一层,它解决的核心问题是超长上下文导致Token爆炸。
也就是说第二条路很容易导致过量的Token消耗和不准确的上下文,除非自己手动维护
OpenClaw 支持的 Embedding,大体可以分成两类。第一类是 Remote Embeddings,比如 OpenAI、Gemini、Voyage、Mistral 这一类云端服务,前提通常是你得有对应的 API Key。第二类是 Local Embeddings,会用到 node-llama-cpp。如果要走本地路线,通常要满足几个条件memorySearch.provider = localmemorySearch.local.modelPath 可用,而且本地确实有一个能跑的 GGUF embedding model,比如 bge-smallgte-smalle5-small。
需要注意的是,Embedding 本身不会写回 memory 文件。它被存在sqlite里:
memory/main.sqlite
你可以把它理解成一组 text chunk + embedding vector 的对应关系。文件仍然是源数据,向量索引只是为了花费更少的token、至于准不准肯定是没有直接读原文件准的。
能力系统:Tools、Skills 与 Plugins
Tools 是 Agent 的能力接口,也就是 LLM 可调用的能力 API。它的基本运行方式并不复杂,可以概括成下面这条链:
LLM reasoning
↓
tool selection
↓
execute tool
↓
return result
LLM 先判断当前任务需要什么能力,再选择工具执行,最后把结果带回到推理过程里。OpenClaw 内置的工具范围通常包括 filesystem、runtime、web、browser、messaging、memory、sessions、cron、nodes 这些类别,覆盖的已经不只是“查信息”,而是完整的执行能力。
Tools 提供的是通用系统能力,Skills 是业务层的扩展。它通常会把一组工具、流程和约定封装起来,让 Agent 能直接完成某类具体任务,比如发推、抓热点、发邮件,而不是每次都从底层能力重新拼一遍。
两者的区别不难理解Tools 解决的是“能做什么”,Skills 解决的是“这件事具体怎么做”。前者偏系统层,后者偏应用层。
但我觉得这个设计并不是很好,有很大的心智理解负担,我一直会去想就不能直接设计成同一种抽象概念吗?
Plugins 则不是在扩展某个 Agent 的任务能力,而是在扩展 OpenClaw 这个本身。比如模型提供商、消息通道、外部集成,通常都属于 Plugin 的范畴。像 OpenAI provider、Telegram adapter、Discord adapter,本质上都是在给平台增加新的底层连接能力。
这也是它和 Skills 最容易混淆、但又最需要分清的地方Plugins 改的是 OpenClaw自身边界Skills 改的是 Agent 的行为边界。一个偏基础设施,一个偏任务执行。
运行边界:Workspace、Multi-Agent 与会话调度
Workspace 就是 Agent 的工作目录,也是它的状态容器。Memory、Sessions、Skillsnode_modules、缓存、日志,通常都会堆在这里。你可以把它理解成某个 Agent 的“Home”(为什么是某个?因为OpenClaw是多Agent架构):不仅放代码和配置,也放它运行过程中不断积累出来的痕迹和状态。
所以 Workspace 在 OpenClaw 里不是一个普通文件夹,而是 Agent 得以持续存在的基础。
而OpenClaw 的 Multi-Agent,本质上就是多个独立 Agent 共用同一个 Gateway。它们表面上挂在同一套入口下面,但内部通常还是各自维护自己的 workspace、session、memory 以及 tool 配置。
结构上大致可以理解成这样:
Gateway
├── agent A
├── agent B
└── agent C
Session管理
但只把多个 Agent 挂在同一个 Gateway 下面还不够,关键还在于它们怎么彼此协作。
OpenClaw 给出的做法,是允许 Agent 直接操作会话本身。像 sessions_list、sessions_history、sessions_send 这一类能力,本质上就是在把 session 当成一个可调度、可通信的对象,而不只是上下文背景。
这套机制最有价值的地方,在于它让 agent 之间的通信和 sub-agent 的调度都有了明确入口。
换句话说,OpenClaw 不只是能聊天,还能把“会话”本身变成编排单元。
它最终提供的核心能力,可以概括成:
agent → agent communication
Sub Agent
再往前走一步,这种会话编排能力自然就会落到一种更具体的形态上,也就是 Sub Agent。
它本质上就是一个临时拉起的 Agent Session。你可以把它理解为“把某个子任务外包出去,等它做完再把结果收回来”。
它不是长期驻留的主 Agent,而是为了某个任务短时间存在的执行单元。
它的典型流程通常是:
spawn
↓
send task
↓
child agent executes
↓
return result
所以 Sub Agent 的两个核心特征很明确:生命周期短,而且强任务导向。
它的为了把复杂任务拆开处理。
Workflow
这些是我从几个视角分别拆解出来的Workflow。
Message -> Response Out

ToolCall

Scheduled Automation & Cron

Installing Plugin & Activating
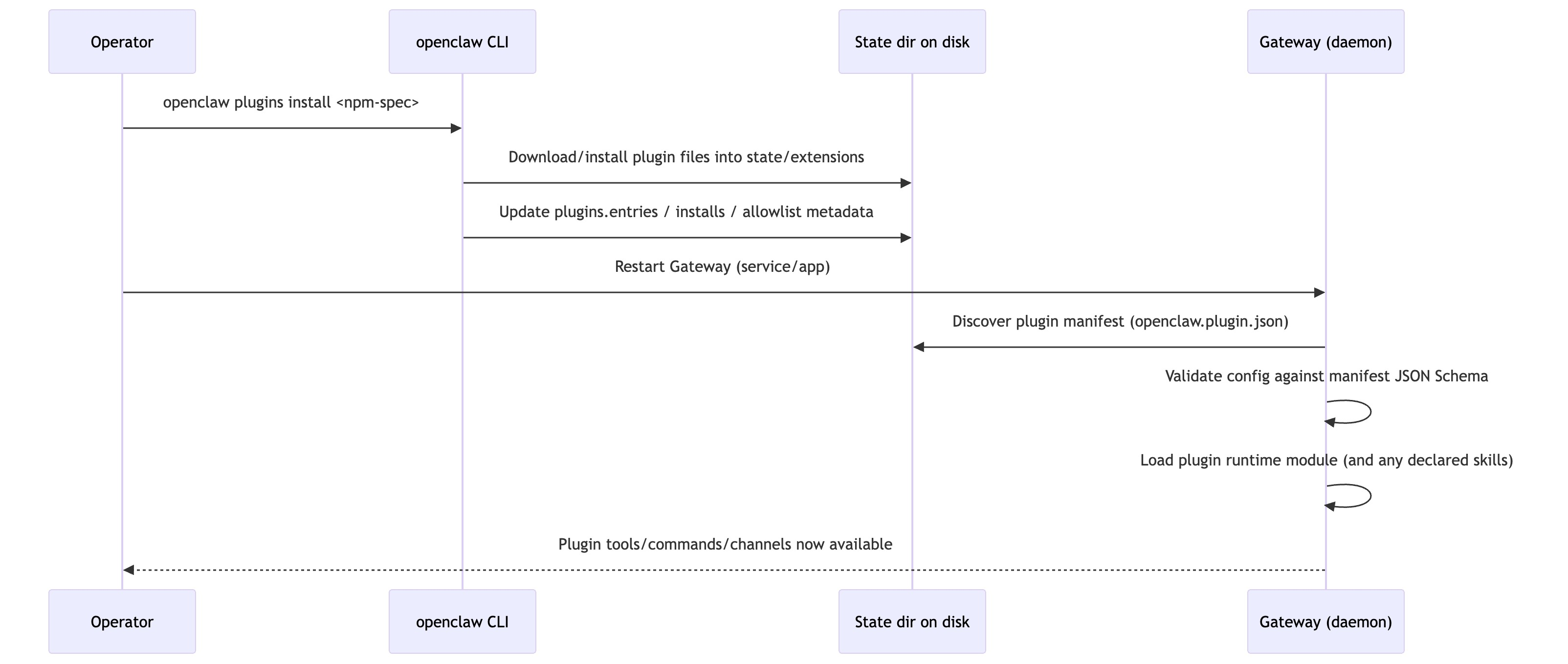
OpenClaw 真正在做什么
如果一定要概括 OpenClaw 的设计哲学,我会认为有三个关键词local-first、file-based memory、tool-driven agents。它并不是先假设一切都要交给远端服务,而是先把状态、记忆和能力组织在本地文件系统与工具调用之上。
它更接近:
AI operating system
而不是:
RAG application
也正因为如此,理解 OpenClaw 不能只从“它能不能检索知识”来切入,而要从“它怎样管理 Agent 的状态、上下文、能力和执行边界”来切入。
从系统分层来看,OpenClaw 大致可以抽象成下面这条链:
Platform
↓
Gateway
↓
Agent Runtime (Pi)
↓
Sessions
↓
Memory
↓
Tools / Skills
↓
External Systems
越往上越偏平台和运行时,越往下越接近具体能力与外部世界。这样看,Gateway、Runtime、Session、Memory、Tools、Skills 之间的关系就会清楚很多。
闲谈
哎,我觉得很多应用层公司和大厂,其实甚至都有更优秀的上下文管理和 Agent 调度方案,包括之前我自己也做过类似的东西。但最后真正把这套思路拿出来、开源出来、并且直接放到用户电脑上的,是 OpenClaw。我越来越觉得,真正能对世界产生贡献的,往往不只是能力本身,而是创造力、利他心,以及愿意把好东西交还给更多人的那种选择。
欢迎加入我们的OpenClaw调优社区,这里有很多的技术大牛,也有各种寻求帮助的用户。